Note
Go to the end to download the full example code.
Survival Analysis: Cox Regression#
Cox Proportional Hazards Regression#
Cox Proportional Hazards (CoxPH) regression is to describe the survival according to several corvariates. The difference between CoxPH regression and Kaplan-Meier curves or the logrank tests is that the latter only focus on modeling the survival according to one factor (categorical predictor is best) while the former is able to take into consideration any covariates simultaneously, regardless of whether they're quantitive or categorical. The model is as follows:
where,
\(\eta = x\beta.\)
\(t\) is the survival time.
\(h(t)\) is the hazard function which evaluates the risk of dying at time \(t\).
\(h_0(t)\) is called the baseline hazard. It describes value of the hazard if all the predictors are zero.
\(beta\) measures the impact of covariates.
Consider two cases \(i\) and \(i'\) that have different \(x\) values. Their hazard function can be simply written as follow
and
The hazard ratio for these two cases is
which is independent of time.
Lung Cancer Dataset Analysis#
We are going to apply best subset selection to the NCCTG Lung Cancer Dataset from https://www.kaggle.com/ukveteran/ncctg-lung-cancer-data. This dataset consists of survival information of patients with advanced lung cancer from the North Central Cancer Treatment Group. The proportional hazards model allows the analysis of survival data by regression modeling. Linearity is assumed on the log scale of the hazard. The hazard ratio in Cox proportional hazard model is assumed constant.
First, we load the data.
import pandas as pd
data = pd.read_csv('cancer.csv')
data = data.drop(data.columns[[0, 1]], axis=1)
print(data.head())
time status age sex ph.ecog ph.karno pat.karno meal.cal wt.loss
0 306 2 74 1 1.0 90.0 100.0 1175.0 NaN
1 455 2 68 1 0.0 90.0 90.0 1225.0 15.0
2 1010 1 56 1 0.0 90.0 90.0 NaN 15.0
3 210 2 57 1 1.0 90.0 60.0 1150.0 11.0
4 883 2 60 1 0.0 100.0 90.0 NaN 0.0
Then we remove the rows containing any missing data. After that, we have a total of 168 observations.
data = data.dropna()
print(data.shape)
(168, 9)
Then we change the categorical variable ph.ecog into dummy variables:
data['ph.ecog'] = data['ph.ecog'].astype("category")
data = pd.get_dummies(data)
data = data.drop('ph.ecog_0.0', axis=1)
print(data.head())
time status age sex ... wt.loss ph.ecog_1.0 ph.ecog_2.0 ph.ecog_3.0
1 455 2 68 1 ... 15.0 False False False
3 210 2 57 1 ... 11.0 True False False
5 1022 1 74 1 ... 0.0 True False False
6 310 2 68 2 ... 10.0 False True False
7 361 2 71 2 ... 1.0 False True False
[5 rows x 11 columns]
We split the dataset into a training set and a test set. The model is going to be built on the training set and later we will test the model performance on the test set.
import numpy as np
np.random.seed(0)
ind = np.linspace(1, 168, 168) <= round(168 * 2 / 3)
train = np.array(data[ind])
test = np.array(data[~ind])
print('train size: ', train.shape[0])
print('test size:', test.shape[0])
train size: 112
test size: 56
Model Fitting#
The CoxPHSurvivalAnalysis() function in the abess package allows we to perform best subset selection in a highly efficient way.
By default, the function implements the abess algorithm with the support size (sparsity level)
changing from 0 to \(\min\{p,n/\log(n)p \}\) and the best support size is determined by EBIC.
You can change the tuneing criterion by specifying the argument ic_type and the support size by support_size.
The available tuning criteria now are "gic", "aic", "bic",
"ebic". Here we give an example.
from abess import CoxPHSurvivalAnalysis
model = CoxPHSurvivalAnalysis(ic_type='gic')
model.fit(train[:, 2:], train[:, :2])
After fitting, the coefficients are stored in model.coef_,
and the non-zero values indicate the variables used in our model.
print(model.coef_)
[ 0. -0.379564 0.02248522 0. 0. 0.
0.43729712 1.42127851 2.42095755]
This result shows that 5 variables (the 2nd, 3rd, 7th, 8th, 9th) are chosen into the Cox model. Then a further analysis can be based on them.
More on the results#
Hold on, we haven’t finished yet. After getting the estimator, we can further do more exploring work. For example, you can use some generic steps to quickly draw some information of those estimators.
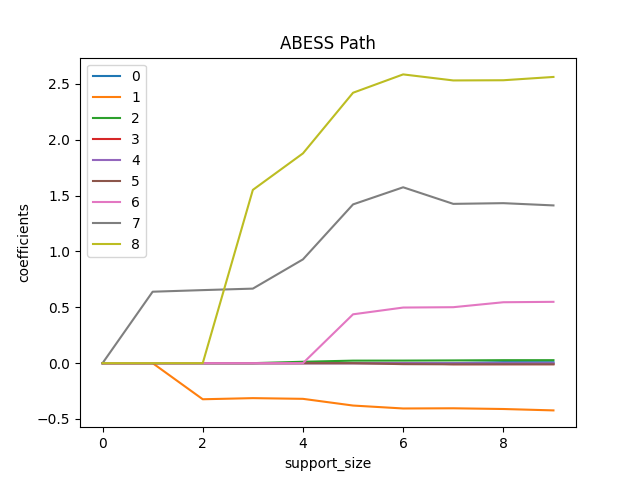
Simply fix the support_size in different levels, we can plot a path
of coefficients like:
import matplotlib.pyplot as plt
coef = np.zeros((10, 9))
ic = np.zeros(10)
for s in range(10):
model = CoxPHSurvivalAnalysis(support_size=s, ic_type='gic')
model.fit(train[:, 2:], train[:, :2])
coef[s, :] = model.coef_
ic[s] = model.eval_loss_
for i in range(9):
plt.plot(coef[:, i], label=i)
plt.xlabel('support_size')
plt.ylabel('coefficients')
plt.title('ABESS Path')
plt.legend()
plt.show()
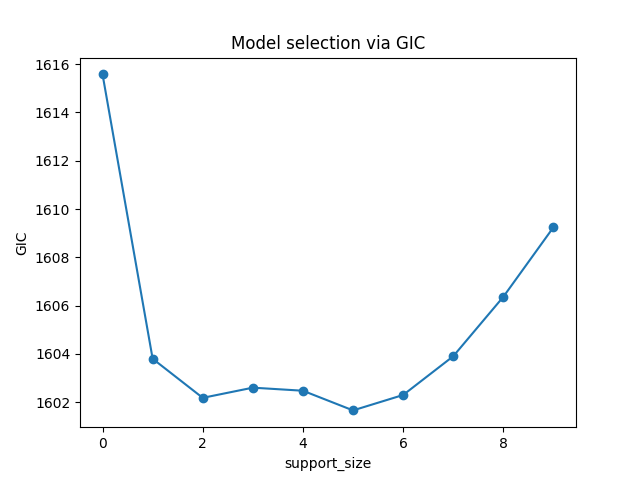
Or a view of evolution of information criterion:
plt.plot(ic, 'o-')
plt.xlabel('support_size')
plt.ylabel('GIC')
plt.title('Model selection via GIC')
plt.show()
Prediction is allowed for all the estimated model.
Just call predict() function under the model you are interested in.
The values it return are \(\exp(\eta)=\exp(x\beta)\), which is part of Cox PH hazard function.
Here we give the prediction on the test data.
[11.0015887 11.97954111 8.11705612 3.32130081 2.9957487 3.23167938
5.88030263 8.83474265 6.94981468 2.79778448 4.80124013 8.32868839
6.18472356 7.36597245 2.79540785 7.07729092 3.57284073 6.95551265
3.59051464 8.73668805 3.51029827 4.28617052 5.21830511 5.11465146
2.92670651 2.31996184 7.04845409 4.30246362 7.14805341 3.83570919
6.27832924 6.54442227 8.39353611 5.41713824 4.17823079 4.01469621
8.99693705 3.98562593 3.9922459 2.79743549 3.47347931 4.40471703
6.77413094 4.33542254 6.62834299 9.99006885 8.1177072 20.28383502
14.67346807 2.27915833 5.78151822 4.31221688 3.25950636 6.99318596
7.4368521 3.86339324]
With these predictions, we can compute the hazard ratio between every two observations (by dividing their values). And, we can also compute the C-Index for our model, i.e., the probability that, for a pair of randomly chosen comparable samples, the sample with the higher risk prediction will experience an event before the other sample or belong to a higher binary class.
0.6839080459770115
On this dataset, the C-index is about 0.68.
We can also perform prediction in terms of survival or cumulative hazard function. Here we choose the 9th predictor and we want to see how positive or negative status would affect the survival function for each patient.
surv_fns = model.predict_survival_function(train[:, 2:])
time_points = np.quantile(train[:, 0], np.linspace(0, 0.6, 100)).astype(float)
legend_handles = []
legend_labels = []
_, ax = plt.subplots(figsize=(9, 6))
for fn, label in zip(surv_fns, train[:, 8].astype(int)):
line, = ax.step(time_points, fn(time_points), where="post",
color="C{:d}".format(label), alpha=0.5)
if len(legend_handles) <= label:
name = "positive" if label == 1 else "negative"
legend_labels.append(name)
legend_handles.append(line)
ax.legend(legend_handles, legend_labels)
ax.set_xlabel("time")
ax.set_ylabel("Survival probability")
ax.set_title("Survival curve plot")
ax.grid(True)
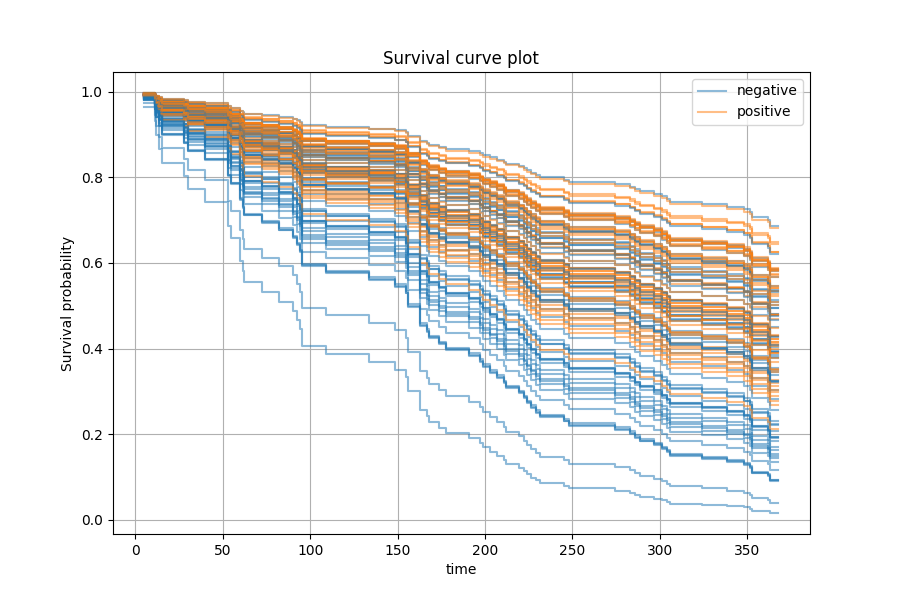
The graph above shows that patients with positive status on the 9th predictor tend to have better prognosis.
The abess R package also supports CoxPH regression.
For R tutorial, please view
https://abess-team.github.io/abess/articles/v05-coxreg.html.
sphinx_gallery_thumbnail_number = 3
Total running time of the script: (0 minutes 0.556 seconds)