Computational Tips#
The generic splicing technique certifiably guarantees the best subset can be selected in a polynomial time. In practice, the computational efficiency can be improved to handle large scale datasets. The tips for computational improvement are applicable for:
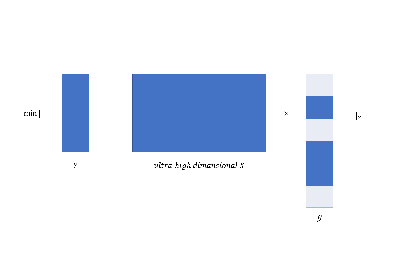
ultra-high dimensional data via
feature screening;
focus on important variables;
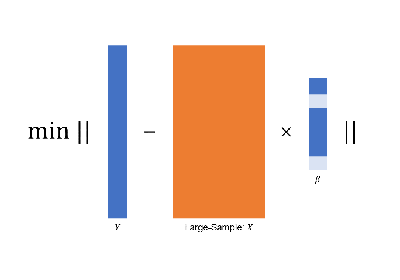
large-sample data via
golden-section searching;
early-stop scheme;
sparse inputs via
sparse matrix computation;
specific models via
covariance update for
LinearRegressionandMultiTaskRegression;quasi Newton iteration for
LogisticRegression,PoissonRegression,CoxRegression, etc.
More importantly, the technique in these tips can be use simultaneously.
For example, abess allow algorithms to use both feature screening and golden-section searching such that
algorithms can handle datasets with large-sample and ultra-high dimension.
The following contents illustrate the above tips.
Besides, abess efficiently implements warm-start initialization and parallel computing,
which are very useful for fast computing.
To help use leverage them, we will also describe their implementation details in the following.