Note
Go to the end to download the full example code.
Principal Component Analysis#
This notebook introduces what is adaptive best subset selection principal component analysis (SparsePCA) and uses a real data example to show how to use it.
PCA#
Principal component analysis (PCA) is an important method in the field of data science, which can reduce the dimension of data and simplify our model. It actually solves an optimization problem like:
where \(\Sigma = X^TX / (n-1)\) and \(X\) is the centered sample matrix. We also denote that \(X\) is a \(n\times p\) matrix, where each row is an observation and each column is a variable.
Then, before further analysis, we can project \(X\) to \(v\) (thus dimension reduction), without losing too much information.
However, consider that:
The PC is a linear combination of all primary variables (\(Xv\)), but sometimes we may tend to use less variables for clearer interpretation (and less computational complexity);
It has been proved that if \(p/n\) does not converge to \(0\), the classical PCA is not consistent, but this would happen in some high-dimensional data analysis.
For example, in gene analysis, the dataset may contain plenty of genes (variables) and we would like to find a subset of them, which can explain most information. Compared with using all genes, this small subset may perform better on interpretation, without losing much information. Then we can focus on these variables in further analysis.
When we are trapped by these problems, a classical PCA may not be a best choice, since it uses all variables. One of the alternatives is SparsePCA, which is able to seek for principal component with a sparsity limitation:
where \(s\) is a non-negative integer, which indicates how many primary variables are used in principal component. With SparsePCA, we can search for the best subset of variables to form principal component and it retains consistency even under \(p>>n\). And we make two remarks:
Clearly, if \(s\) is equal or larger than the number of primary variables, this sparsity limitation is actually useless, so the problem is equivalent to a classical PCA.
With less variables, the PC must have lower explained variance. However, this decrease is slight if we choose a good \(s\) and at this price, we can interpret the PC much better. It is worthy.
In the next section, we will show how to perform SparsePCA.
Real Data Example (Communities and Crime Dataset)#
Here we will use real data analysis to show how to perform SparsePCA. The data we use is from UCI: Communities and Crime Data Set and we pick up its 99 predictive variables as our samples.
Firstly, we read the data and pick up those variables we are interested in.
1994
99
Model fitting#
To build an SparsePCA model, we need to give the target sparisty to its support_size argument. Our program supports adaptively finding a best sparisty in a given range.
Fixed sparsity#
If we only focus on one fixed sparsity, we can simply give a single integer to fit on this situation. And then the fitted sparse principal component is stored in SparsePCA.coef_:
model = SparsePCA(support_size=20)
Give either \(X\) or \(\Sigma\) to model.fit(), the fitting process will start. The argument is_normal = False here means that the program will not normalize \(X\). Note that if both \(X\) and \(Sigma\) are given, the program prefers to use \(X\).
After fitting, model.coef_ returns the sparse principal component and its non-zero positions correspond to variables used.
temp = np.nonzero(model.coef_)[0]
print('sparsity: ', temp.size)
print('non-zero position: \n', temp)
print(model.coef_.T)
sparsity: 20
non-zero position:
[ 3 4 5 17 28 49 55 56 57 58 59 60 61 62 65 66 67 69 90 96]
[[ 0. 0. 0. -0.20905321 0.15082783 0.26436836
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.13962306
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0.14795039 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0.13366389 0. 0. 0. 0.
0. 0.28227473 0.28982717 0.29245315 0.29340846 -0.27796975
0.27817835 0.20793385 0.19020622 0. 0. 0.15462671
-0.13627653 0.25848049 0. -0.14433668 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0.27644605 0. 0. 0. 0. 0.
0.16881151 0. 0. ]]
Adaptive sparsity#
What's more, abess also support a range of sparsity and adaptively choose the best-explain one. However, usually a higher sparsity level would lead to better explaination.
Now, we need to build an \(s_{max} \times 1\) binomial matrix, where \(s_{max}\) indicates the max target sparsity and each row indicates one sparsity level (i.e. start from \(1\), till \(s_{max}\)). For each position with \(1\), abess would try to fit the model under that sparsity and finally give the best one.
# fit sparsity from 1 to 20
support_size = np.ones((20, 1))
# build model
model = SparsePCA(support_size=support_size)
model.fit(X, is_normal=False)
# results
temp = np.nonzero(model.coef_)[0]
print('chosen sparsity: ', temp.size)
print('non-zero position: \n', temp)
print(model.coef_.T)
chosen sparsity: 20
non-zero position:
[11 12 17 19 20 21 27 29 30 35 36 44 76 78 79 80 81 82 83 84]
[[ 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. -0.27618663
-0.23703262 0. 0. 0. 0. 0.18384733
0. -0.2275236 -0.21204903 -0.19753942 0. 0.
0. 0. 0. 0.21358573 0. 0.18270928
-0.18928695 0. 0. 0. 0. 0.1760962
-0.17481418 0. 0. 0. 0. 0.
0. 0. -0.18581084 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0.23804122 0.
-0.2415995 -0.24785373 -0.24947283 -0.23938391 -0.23605314 -0.28015859
-0.23841083 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. ]]
Because of warm-start, the results here may not be the same as fixed sparsity.
Then, the explained variance can be computed by:
explained ratio: [[0.16920803]]
More on the results#
We can give different target sparsity (change s_begin and s_end) to get different sparse loadings. Interestingly, we can seek for a smaller sparsity which can explain most of the variance.
In this example, if we try sparsities from \(0\) to \(p\), and calculate the ratio of explained variance:
num = 30
i = 0
sparsity = np.linspace(1, p - 1, num, dtype='int')
explain = np.zeros(num)
Xc = X - X.mean(axis=0)
for s in sparsity:
model = SparsePCA(
support_size=np.ones((s, 1)),
exchange_num=int(s),
max_iter=50
)
model.fit(X, is_normal=False)
Xv = Xc @ model.coef_
explain[i] = Xv.T @ Xv
i += 1
print('80%+ : ', sparsity[explain > 0.8 * explain[num - 1]])
print('90%+ : ', sparsity[explain > 0.9 * explain[num - 1]])
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
/home/docs/checkouts/readthedocs.org/user_builds/abess/checkouts/latest/docs/Tutorial/2-pca/plot_6_PCA.py:172: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
explain[i] = Xv.T @ Xv
80%+ : [31 34 37 41 44 47 51 54 57 61 64 67 71 74 77 81 84 87 91 94 98]
90%+ : [41 44 47 51 54 57 61 64 67 71 74 77 81 84 87 91 94 98]
If we denote the explained ratio from all 99 variables as 100%, the curve indicates that at least 31 variables can reach 80% (blue dashed line) and 41 variables can reach 90% (red dashed line).
import matplotlib.pyplot as plt
plt.plot(sparsity, explain)
plt.xlabel('Sparsity')
plt.ylabel('Explained variance')
plt.ylabel('Sparsity versus Explained Variance')
ind = np.where(explain > 0.8 * explain[num - 1])[0][0]
plt.plot([0, sparsity[ind]], [explain[ind], explain[ind]], 'b--')
plt.plot([sparsity[ind], sparsity[ind]], [0, explain[ind]], 'b--')
plt.text(sparsity[ind], 0, str(sparsity[ind]))
plt.text(0, explain[ind], '80%')
ind = np.where(explain > 0.9 * explain[num - 1])[0][0]
plt.plot([0, sparsity[ind]], [explain[ind], explain[ind]], 'r--')
plt.plot([sparsity[ind], sparsity[ind]], [0, explain[ind]], 'r--')
plt.text(sparsity[ind], 0, str(sparsity[ind]))
plt.text(0, explain[ind], '90%')
plt.plot([0, p], [explain[num - 1], explain[num - 1]],
color='gray', linestyle='--')
plt.text(0, explain[num - 1], '100%')
plt.show()
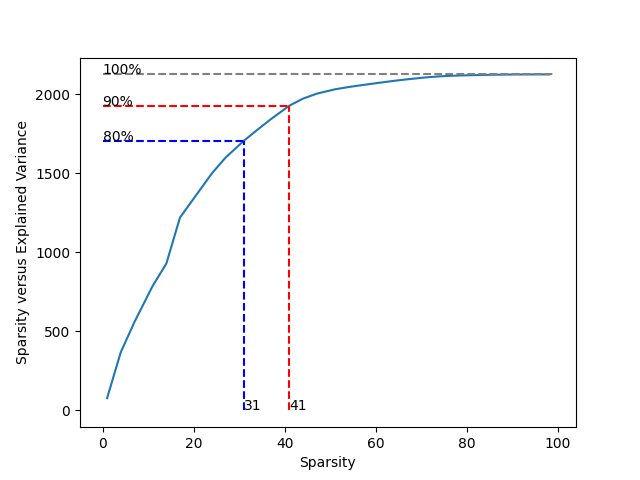
This result shows that using less than half of all 99 variables can be close to perfect. For example, if we choose sparsity 31, the used variables are:
model = SparsePCA(support_size=31)
model.fit(X, is_normal=False)
temp = np.nonzero(model.coef_)[0]
print('non-zero position: \n', temp)
non-zero position:
[ 2 11 12 15 17 19 20 21 22 25 27 28 29 30 31 32 35 36 42 43 44 45 49 76
78 79 80 81 82 83 84]
Extension: Group PCA#
Group PCA#
Furthermore, in some situations, some variables may need to be considered together, that is, they should be "used" or "unused" for PC at the same time, which we call "group information". The optimization problem becomes:
where we suppose there are \(G\) groups, and the \(g\)-th one correspond to \(v_g\), \(v = [v_1^{\top},v_2^{\top},\cdots,v_G^{\top}]^{\top}\). Then we are interested to find \(s\) (or less) important groups.
Group problem is extraordinarily important in real data analysis. Still take gene analysis as an example, several sites would be related to one character, and it is meaningless to consider each of them alone.
SparsePCA can also deal with group information. Here we make sure that variables in the same group address close to each other (if not, the data should be sorted first).
Simulated Data Example#
Suppose that the data above have group information like:
Group 0: {the 1st, 2nd, ..., 6th variable};
Group 1: {the 7th, 8th, ..., 12th variable};
...
Group 15: {the 91st, 92nd, ..., 96th variable};
Group 16: {the 97th, 98th, 99th variables}.
Denote different groups as different numbers:
[ 0 0 0 0 0 0 1 1 1 1 1 1 2 2 2 2 2 2 3 3 3 3 3 3
4 4 4 4 4 4 5 5 5 5 5 5 6 6 6 6 6 6 7 7 7 7 7 7
8 8 8 8 8 8 9 9 9 9 9 9 10 10 10 10 10 10 11 11 11 11 11 11
12 12 12 12 12 12 13 13 13 13 13 13 14 14 14 14 14 14 15 15 15 15 15 15
16 16 16]
And fit a group sparse PCA model with additional argument group=g_info:
model = SparsePCA(support_size=np.ones((6, 1)), group=g_info)
model.fit(X, is_normal=False)
The result comes to:
print(model.coef_.T)
temp = np.nonzero(model.coef_)[0]
temp = np.unique(g_info[temp])
print('non-zero group: \n', temp)
print('chosen sparsity: ', temp.size)
[[-0.04658786 -0.08867352 -0.04812687 0.20196704 -0.15626888 -0.24420959
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
-0.03874654 -0.12602642 -0.05981463 -0.11432162 -0.13193075 -0.13909102
-0.14829175 -0.28195208 -0.28747947 -0.28866805 -0.28772941 0.25581611
-0.25726917 -0.19242565 -0.17526315 -0.08740502 -0.06877806 -0.14679731
0.1392863 -0.24410922 -0.10815193 0.14329729 -0.03971005 0.00862702
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
-0.26329492 0.12107731 0.07789811 0.04291127 0.0606106 -0.00599532
0. 0. 0. ]]
non-zero group:
[ 0 8 9 10 11 15]
chosen sparsity: 6
Hence we can focus on variables in Group 0, 8, 9, 10, 11, 15.
Extension: Multiple principal components#
Multiple principal components#
In some cases, we may seek for more than one principal components under sparsity. Actually, we can iteratively solve the largest principal component and then mapping the covariance matrix to its orthogonal space:
where \(\Sigma\) is the currect covariance matrix and \(v\) is its (sparse) principal component. We map it into \(\Sigma'\), which indicates the orthogonal space of \(v\), and then solve the sparse principal component again.
By this iteration process, we can acquire multiple principal components and they are sorted from the largest to the smallest. In our program, there is an additional argument number, which indicates the number of principal components we need, defaulted by 1. Now the support_size is shaped in \(s_{max}\times \text{number}\) and each column indicates one principal component.
model = SparsePCA(support_size=np.ones((31, 3)))
model.fit(X, is_normal=False, number=3)
model.coef_.shape
(99, 3)
Here, each column of the model.coef_ is a sparse PC (from the largest to the smallest), for example the second one is that:
model.coef_[:, 1]
array([ 0. , 0. , 0. , -0.19036307, 0.1546593 ,
0.22909258, 0. , 0. , 0. , 0. ,
0. , 0.15753326, 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0.10274482, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.11546037,
0. , 0. , 0.11150352, 0.1198269 , 0.12927627,
0.27435616, 0.28022643, 0.28220338, 0.28150593, -0.25022706,
0.24872368, 0.17726069, 0.15920166, 0. , 0. ,
0.12531301, -0.13462701, 0.22695789, 0.11034058, -0.14302014,
0. , 0. , -0.11505769, 0. , 0. ,
0. , 0. , 0. , 0.10140235, 0.10764364,
0.10731785, 0. , 0. , 0. , 0. ,
0. , 0.1151606 , 0. , 0. , 0. ,
0.26358121, -0.11368877, 0. , 0. , 0. ,
0. , 0.16906762, 0.11129358, 0. ])
If we want to compute the explained variance of them, it is also quite easy:
explained ratio: 0.4601845965703712
R tutorial#
For R tutorial, please view https://abess-team.github.io/abess/articles/v08-sPCA.html.
Total running time of the script: (0 minutes 4.785 seconds)